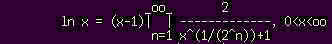|
[english] :
[zurück] :
[Anfang] |
|
NETSCAPE u.dgl. Zeugs
HINWEIS:
Die Programme und Texte sind überwiegend englischsprachig abgefaßt.
Alle Assemblerquellen sind auf "nasm" (0.98-3.1,
tar.bz2-Archiv ggf. per mail) &
"asmutils" 0.09+ für Linux-i386/ELF-Systeme abgestimmt.
Hier angegebene Programme und Texte sind sämtlich zur ausschließlich nicht-kommerziellen
Verwendung entsprechend der QT-Lizenz sowie u.U. ergänzenden Texten in
den einzelnen Archiven freigegeben, patentrechtliche Verwertung (bescheuert, aber man muß z.Zt. ja
wohl mit allem rechnen...) behalte ich mir vor. Anderes unterliegt den Bestimmungen der jeweiligen Autoren
und wird hier nur hilfsweise bereitgehalten. Software und Texte befinden sich in experimentellem Zustand,
Zusagen werden - auch in Gestalt ggf. beiliegender Dokumentation - nicht gemacht, Gewährleistung
ist ausgeschlossen. Falls diese Voraussetzungen nicht vollständig anerkannt und eingehalten werden
sowie unwidersprochen bleiben, ist Nutzungserlaubnis in Gesamtheit nicht gewährt.
| [allgemein] : [arithmetik] : [beispiele] : [assembler] |
umount /dev/cdrom eject echo "<enter> .." read a retract mount /dev/cdrom /cdrom iso9660Weiter keine Besonderheiten, darum neben der kommentierten Assemblerquelle nicht gesondert dokumentiert.
input x, p := 0, a := 0 loop 1 to #bits(x)/2 shift left x into a 2 places shift left p one place if a > 2*p then a:=a-(2*p+1); p:=p+1 end return pDieser Algorithmus aus den dunklen Tiefen meiner Erinnerung an den "ZX81" - und die Zeit vor dem Taschenrechner, denn dies ist exakt die Abbildung des schriftlichen Rechenverfahrens, benötigt etwa dieselbe Rechenzeit, wie die bitweise Division. In jedem Falle ist er wesentlich Schneller, als die Vorgehensweise nach Newton - die für Quadratwurzeln allenfalls ein leicht überschaubares Beispiel ihrer selbst abgibt.
o.a. unendliches Produkt nach dem Algorithmus BSW (borisi-shnider-wasserman) läßt sich leicht in Assemblercode (lib4th) oder auch hi-level Forth (F4) umsetzen, es konvergiert schnell und liefert damit sehr genaue Ergebnisse. Abbruch bei Überlauf rsp. sobald im Rahmen der möglichen Genauigkeit x^(1/(2^n)) == x^(1/(2^(n-1))) erreicht ist. - Z.B. liefert die entspr. Procedur im F4 mit reellen Zahlen in Form 63/64-bit-genauer Brüche ln(2) nach 43 Iterationen mit (min.) 16-stelliger Genauigkeit.
Abbruch, wenn x/n Null wird rsp. nach Erreichen der größten darstellbaren Fakultät von n, n=33 für 128-Bit-Zahlen. Der Fehler liegt dann (soweit sich das mit einem alten Taschenrechner kontrollieren ließ) unter +/- 10^-10; der Rechengang war im allgemeinen weit vor Ereichen der Grenze für n! beendet.
Abruch, wenn m im Rahmen der benutzten Bitzahl Null ist, oder bei einem vorzugebenden Maximum an Schleifendurchgängen, 255 im lib4th-Beispiel.
Abbruch, wenn der Ausdruck x(n) im Rahmen des benutzten Zahlenformats Null wird rsp. nach Erreichen der größten darstellbaren Fakultät von 2n, n=16 bei 128-Bit-Zahlen.
/* ; word header for a 4th primitive .macro __CODE lex=0,name,label,prev=0,mod=0 __DATASEG__ .long \label .ifndef n0 n0: .long 0 /* ; set linkage base .else .long 10001b /* ; link to previous header .endif 10001: n\label: .byte (10000f-1-.)|(\lex&-32) .ascii "\name" 10000: _NTOP =. /* ; always last of all refs, due to 'preprocessing'! __CODESEG__ .endmVerankerung und Verkettung einer Folge solcher __CODE-header geschieht hier nun ohne weiteren Eingriff mit Hilfe des Labels <10001>.
%imacro _message 0-*.nolist
%if %0>0
%xdefine _msg_
%rep %0
%xdefine _msg_ _msg_ %{1}
%rotate 1
%endrep
%error "_msg_"
%endif
%endmacro
# -------- schnipp ---------- (nächste zeile muß erste im script sein!)
#! /bin/sh
# hp - Son Mär 18 18:03:22 GMT 2001
# <aumac-nolist> filename hängt "_nolist" an Zeilen mit %macro an
# $1: infile file $1 lesen & ändern
# $1: infile $2:outfile aus $1 die geänderte copie $2 erzeugen
# infile
f=${1}
# eigenen namen ausschließen
[ "$(basename ${f})" == "$(basename ${0})" ]&&exit 0
# outfile; hilfsdatei bei in=out
# sofort fertig wenn kein zeilen-anfang mit "%macro" gefunden
[ -z "${2}" ]&&
{
grep "^\%macro\ " ${f} 2> /dev/null||exit 0
o=${f}$$
}||
{
o=${2}
grep "^\%macro\ " ${f} 2> /dev/null||{ cp ${f} ${o};exit 0; }
}
# Wort-Zerlegung der shell unterbinden, zeilenweise lesen
IFS=
# infile lesen, %macro aufsuchen und "_nolist" anfügen, alles zeilenweise nach outfile
cat -v "${f}"|while read 'i'
do
[ -n "$(echo "${i}"|grep "^\%macro\ "|grep -v "[_\.]nolist")" ]&&
echo "${i}_nolist">>${o}||
echo "${i}">>${o}
done
[ "${o}" == "${f}$$" ]&&mv -f ${o} ${f}
# aumac-nolist <eof>
# -------- schnapp ----------
-u schaltet auf 16-Bit um, -v gibt wie -r die Version an, -l anzahl_zeilen zur Angabe der maximalen Anzahl Ausgabezeilen.
Ein paar Änderungen sind neben den - unentbehrlichen! - Ergänzungen aus
"nasm-0.89e" insbes. gegen Schwachsinn gerichtet, der etwa zur
Unterdrückung des Assembler-Listing ausgerechnet im Fehlerfalle führt!
Die sehr simple Änderung läßt zwar ggf. unbrauchbare Binaerfiles stehen, vor allem aber
bleibt stets auch die erzeugte Liste erhalten. Nur der Abbruch wird unterdrückt,
nicht die eventuelle Ausgabe irgendwelcher Meldungen. Fehler lassen sich dann selbst in (expandierten,
bei "nasm" heißt das "listing") Macros noch aufspüren, wo die sonst als magerer
Hinweis ohne jeden Bezug zur "listing"-Zeile(!) abgesonderten Zeilennummern nicht sonderlich hilfreich waren.
Hinweis auf Fehlerstellen sind solche Zeilen, die bei ordentlichen Operationen in der dritten Spalte
keine Binärdaten aufweisen. Auch sollten die Warn- und Fehlermeldungen nun besonders aufmerksam
beachtet werden.
Beispiel (aus "lib4th" Makefile):
/usr/src/Asm/nasm/nasm -felf -olib4th.o lib4th.asm 2> lib4th.asm.log
cat lib4th.asm.log|grep -v warning && rm lib4th.o || rm lib4th.asm.log
wo mittels Copie der Fehlerausgabe bei Fehlern (nicht "warning"s) die erzeugte Binärdatei entfernt wird.
%macro sonstwas 3
%xdefine p1 %{1}
%xdefine p2 %{2}
%xdefine p3 %{3}
%error "arg 1:p1, 2:p2, 3:p3"
... ; die macro-definition, oder leer, z.b. zur anzeige von variablen
%endm
Die o.g. secundäre Version räumt mit etlichen Fehlern auf, sodaß sich damit
immerhin in gewissen Rahmen arbeiten läßt, d.h. über einfache "utilities" und
ähnliche Spielereien hinaus...